Ещё про «OpenAI», увольнение Сэма Альтмана и его возвращение назад
29 ноября 2023 года

Давайте вернёмся к последней работе «OpenAI» по LLM «Let's Verify Step by Step». Она вышла 31 мая. В авторах числятся Jan Leike и Ilya Sutskever — люди, которые летом стали «лидами» команды «SuperAlignment». Я уже писал пост про статью, но уверен, что многие или пропустили, или забыли — можно ознакомиться тут.

В этой работе обучается модель, генерирующая решения математических задач. При этом, во время тренировки, предлагается «поощрять» нейронку за каждый правильный шаг рассуждения (делается «контроль процесса»). Вместо вознаграждения за правильный окончательный ответ («контроль результата», именно так обучалась «GPT-4»).
Простыми словами: вместо того, чтобы смотреть на всё решение целиком и говорить «Ну, ответ неправильный, поэтому решение — фигня» (как ваш «препод» в «универе»), теперь говорят «Ага, вот эти первые 6 шагов — правильные, а в 7-м — ошибка, из-за которой ответ не получился». Это даёт куда больше полезного сигнала, что приводит к более качественным результатам.
Один из артефактов обучения новым методом: в ходе тренировки, мы получаем модель, которая для каждого отдельного шага решения учится предсказывать, является ли оно корректным. Такая модель может обнаруживать как «галлюцинации», когда модель что-то сказанула, не подумав, так и ошибки в чистой математике, когда задним числом понимаешь, что что-то не сходится.
А теперь давайте сделаем вот такой трюк: через «ChatGPT» сгенерируем тысячу решений задачи, а затем используем упомянутую выше модель-оценщика для того, чтобы выбрать самое правильное. Если «ChatGPT» достаточно умна, чтобы хотя бы раз в 1000 генераций выдавать правильный ответ (не так много и требуем, кстати), а оценщик достаточно хорошо, постфактум, по решению определяет его корректность, то это ведёт к увеличению доли решённых задач.
И действительно: вы можете в этом убедиться на приложенном выше графике. По горизонтали — увеличивается количество генерируемых гипотез, а по вертикали — видим рост качества. Интересно, что оно не выходит на плато: в теории, можно и сто тысяч гипотез генерировать, а качество — лишь улучшится.

А вот — пример задачи из этого датасета (по клику — картинка откроется в полном размере).
Слева вы можете видеть условие. Оно достаточно сложное (уверен, что значимая часть подписчиков даже не знает, как подступиться к проблеме). А справа — генерация решения моделью. Цветом обозначены предсказания модели-оценщика. Зелёный говорит о том, что в строчке модель проблемы не видит, а красный — что предсказывает ошибку.
И действительно: «GPT-4» пытается использовать формулу разности квадратов на шаге 12 для выражения, которое, на самом деле, не является разностью квадратов. Модель вознаграждения обнаруживает эту ошибку.
В теории, на этом шаге можно было бы попросить «GPT-4» перегенерировать ответ. И делать это десятки-сотни раз. Пока оценщик не будет удовлетворён.
TLDR: ничего страшного, если модели требуется несколько попыток на то, чтобы написать правильное решение. Она, в теории, и сама может находить ошибки, которые замечает человек.
Так вот, к чему была эта прелюдия? В «Рейтерс» пишут, что, якобы, катализатором увольнения Альтмана стало письмо сотрудников «OpenAI» совету директоров. В нём говорится о прорыве в исследовании ИИ, которое «может угрожать человечеству».
Правда, «Рейтерс» не смогла ознакомиться с копией письма. А автор(ы) не ответили на запросы о комментариях. Так что, особо, почвы у теории под ногами нет.
Масла в огонь подливает тот факт, что, за сутки до увольнения, Сэм Альтман на оффлайн-саммите сказал следующее:
— Четыре раза за всю историю «OpenAI», и последний раз был вот несколько недель назад, я присутствовал в комнате, когда мы как бы отодвигаем завесу невежества и подталкиваем границу открытий вперед. Сделать это — профессиональная честь на всю жизнь.
Что он там такого увидел?
Согласно новости, модель (система?) Q* смогла решить некоторые математические задачи — сообщил источник на условиях анонимности. Это само по себе выглядит странно: ведь даже в примере выше — пример куда сложнее (это конец средней школы). И, как-будто, никакого прорыва и нет.
Возможно, журналисты всё перепутали. Ну, или история — выдумка.
Теперь о том, как на это смотреть и чего ждать.
- 1). «OpenAI» точно занимается разработкой модели, которая будет осуществлять научные исследования. Они про это пишут открыто;
- 2). Для того, чтобы это произошло, нужно, чтобы модель-учёный умела решать сложные задачи и планировать исследования. Часть этой работы уже сделана — см. статью выше;
- 3). Вся концепция заключается в том, что модель будет генерировать тысячи неправильных кусочков решений, иногда выдавая верные: главное, чтобы их можно было отранжировать в списке гипотез выше, чем мусорные (вспоминайте модель-оценщика выше);
- 4). Для этого, нужно огромное количество мощностей. Поэтому деньги тут решают. «OpenAI», пока, привлекли больше всех инвестиций. И моё видение такое, что через 2 года это станет большим препятствием для входа. Останется 5-10 игроков, кто готов столько денег «сжигать»;
- 5). Вопрос в том, насколько большим будет следующий скачок? Сможет ли модель писать решения на уровне магистра? PhD? Постдока? Доктора наук? Будет ли она ограничена 2-3 доменами или же обобщится на любую научную область, где есть вычисления?;
- 6). Однажды вы проснётесь и слух из новости станет правдой: появится модель, которая будет хотя бы частично (>50%) заменять одного учёного в лаборатории. С этих пор, прогресс начнёт двигаться гораздо быстрее: потому что нанять 100 учёных за день нельзя, а запустить 100500 моделей на кластере за день — можно.
Более подробно с моим видением дальнейшей стратегии «OpenAI» и направлениями, в которых они будут «копать», вы можете ознакомиться в моей недавней лекции «What's next for OpenAI?»:
Тут я, конечно, не предсказал шумиху с увольнением CEO, но много говорю про агентов-исследователей и подход «OpenAI».
А почитать больше спекуляций по поводу Gemini и Q* можно на LessWrong.
Автор и эксперт: «Сиолошная».
Что за сайт для заработка денег подойдёт новичку? Как его создать или купить?
Новое на блоге:
- Сэма Альтмана сначала уволили из «OpenAI», затем устроили в «Микрософт», а после вернули в «OpenAI»
- Новый функционал «ChatGPT Vision»
- «ChatGPT» прекратил регистрацию новых платных пользователей
- Билл Гейтс: 4 изменения, которые ИИ принесёт в нашу жизнь
- Как понять, что фотография человека сгенерирована нейросетью?
Комментарии:
Alexander:
smells like agi spirit
Andrew Grigorev:
На плато - выходит. Шкала x логарифмическая.
Alexander:
осталось оценивать неуверенность интуитивной модели, чтобы не смотреть каждый раз второй
Danya:
а что за датасет у оценщика с задачами по частям?
Сиолошная:
собственный от OpenAI, на 800'000 ВРУЧНУЮ ПРОВЕРЕННЫХ шагов. И кстати, они его выложили в опенсурс: https://github.com/openai/prm800k
BOGDAN:
да на вольфраме нагенерили, стопроц
Danya:
итить...
Alexander:
либо если оценщик не уверен, то уже вызывать калькулятор
Сиолошная:
чет шутки про клозедАи уже смешно да
Denis S:
это прогрев да?
Arseni Anisimovich:
То есть в принципе, если посадить миллион шимпанзе за калькуляторы, то любая задача будет решаема. И на ГПУ тратиться не надо.
Сиолошная:
главное уметь выбирать шимпанзе лучше, чем случайно)
Dinar:
Да можно просто сыпануть атомами в космос, сами организуются)
lemo:
Подход как у ганов получается
Dmitry Anikanov:
Верю не верю типа?
Yr jn:
буквально млн приматов писали текст и один из них написал Гамлет Шекспира
lemo:
Да, есть ещё статейка про воутинг, когда chain of thought только зарождался, но там по другому. Генерим ответ в параллели и потом считаем, сколько раз какой ответ получился. Метод в посте более хороший, но интересно как они при генерации это учитывают
Ivan Chetyrbok:
Скорее там слабый рост, меньше логарифма.
Ivan Chetyrbok:
Это тоже работает, если распределение ответов хотя бы чуть лучше равномерного.
Anton Ryabyh:
вместо вознаграждения за правильный окончательный ответ («контроль результата», именно так обучалась GPT-4).
Разве она не обучается предсказывать один следующий токен вместе с teacher forcing? Т.е. как раз таки получает вознаграждение или пенальти за каждый отдельный шаг. Или существует другая информация?
Сиолошная:
это сложный вопрос чтобы не начать вдаваться в детали, но в целом нет, это уже шаг, отличный от простого предсказания следующего слова.
Можно вот тут верхнеуровневое описание посмотреть (до 59:20)
Andrew Grigorev:
выглядит как log(log(x)), даже если у этой штуки математически нет предела сверху ниже 100%, то практический предел вполне близко и вряд-ли увеличение выборки добавит сколько-нибудь существенно качество
Сиолошная:
с этим согласен, до 100% не дойдет, думаю сойдется к 80+-
Anton Ryabyh:
точно, не подумал, что в rlhf части так и получается
Ivan Chetyrbok:
В том то и дело! И насколько дорогой рост за каждый процент?
Ivan Chetyrbok:
Теоретически может и сколь угодно близко приблизиться, вопрос в стоимости такого приближения.
Vladimir Glazachev:
мы треним предсказывать следующий токен и потом фантуним rl’ем предсказывать ответы с хорошим скором - надо этот скор размазать по всей генерации
в этой статье мы считаем скор не всего ответа, а еще и промежуточных состояний, и даем больше фидбека - скор лучше пропогирует фидбек
в первом случае половина ответа - плохой ответ, во втором - нормальный, просто надо продолжить генерацию
Yr jn:
есть мнение касательно тестов у гпт4 на наличие систем1 и систем2 по аналогии Канемана?
Чуковский:
Карпаты в последнем видосе рассказывал что этого сейчас нет в жпт, но они это исследуют
Andrew Grigorev:
есть ещё ньюанс, что количество различных ответов которые может сгенерировать модель тоже чем-то ограничено... хотя конечно можно параметры сэмплинга ослабить сколько угодно, и в какой-то момент оно сойдется к ситуации с бесконечным числом мартышек набирающих войну и мир
Чуковский:
35:00
Yr jn:
супер интересно как у них там все устроено
Чуковский:
Он это подал под соусом «ну там пацаны в академии чето делают, но это не мы», так что этого мы не узнаем)
Сиолошная:
У меня - нет, но недавно видел статьи на эту тему
Yr jn:
поищу/буду следить
Сиолошная:
Там в названии было System 2, у лекуна в твиттере есть
Andrew Grigorev:
почему он говорит что pretraining надо каждый год с нуля проводить? разве нельзя долить новых данных, и доучить базовую модель пока метрика на валидации по ним не дорастет до валидации по предыдущему датасету?
Сиолошная:
это какой таймкод? 35:00?
Andrew Grigorev:
20:00
Сиолошная:
я думаю он имеет в виду что сейчас их тренируют с нуля раз в год, потому что появляются улучшения + увеличивают размер + лучше данные готовят
Dmitry Anikanov:
пока читал последний пост, сразу ассоциировалась история с разумностью palm.
гугле как сейчас? вообще в конкурентной гонке? тоже б могли суету в топ-менеджменте навести
Kitten Gray:
Вангуем. В каком году ИИ разработает высокотемпературный сверхпроводник?
Dmitry:
На правах Ванги) Пусть будет 2025.
Michael Yudin:
Вот если бы еще научили нейронки формальному доказательству или формальной верификации! Чтоб не мучаться со всякими Coq, Z3 или Isabel )))
Oleg Baranov:
И вот тут вызывают интерес разные новости про ускорение инференса, типа:
1. Исследователи представили метод FastBERT, который используя 0,3% нейронов работает на уровне оригинального BERT, и позволяет достигнуть экспоненциального роста производительности языковых моделей. На тестах получили x78 на CPU и x40 в PyTorch.
2. Lmsys: ускоряем инференс LLM через параллельное декодирование Lookahead. Герганов уже внедряет в llama.cpp
Если совокупный прогресс в алгоритмах инференса и в железе даст необходимый буст, и для каждого ответа ЛЛМ будет успевать строить и оценивать деревья вариантов решения из миллионов узлов, то может мы придём к тем же сверхчеловеческим способностям, как и у Alphago/Allhafold.
Oleg Baranov:
Причём скорее всего "разработает" чисто умозрительно, без всякой экспериментальной базы, как Alphafold просто результат свёртывания абстрактного белка быстро предсказывает.
Дмитрий:
А если выбирать самый вероятный токен (а не рандомно из нескольких вероятных), то на сколько это повышает процент правильно решённых задач?
BOGDAN:
поняли? а дальше думойте
Adonis:
https://t.me/rozetked/17344
Это оно? Сверх интеллект создали?
Сиолошная:
нет, это была предпосылка, ща про это пишу
Vlad:
Я забыл, там в исследовании это прямой аутпут модели без прослоек вроде код интерпретатора?
Спрашиваю потому что через пару недель вышел код, и работает по такой же логике пошаговой, итеративной, с учетом ошибок
Сиолошная:
да, прямой аутпут, без вызова плагинов или инстурментов
не понял, что вышло?
Askh:
А нормально, что я смог продлить подписку на gpt4
Если платеж отменили
BOGDAN:
отменили новые
Askh:
А, ну отлично=)
Andrey:
https://twitter.com/ylecun/status/1727375590423232880?t=cu1Fxq4RJkjLIH5wc1Bj1g&s=19 вот ещё интересная статья появилась на днях
𝕆𝕃𝔼𝔾 𝕂𝕆𝕄𝔸ℝ𝕆𝕍:
"which can be a tricky task" ох уж и словоблуд GPT
BOGDAN:
бан
Alex Rudenko:
Коллеги, а есть способ обходить ограничение в 40 запросов у GPT 4 чи не?
BOGDAN:
есть https://t.me/llmers/8
Alex Rudenko:
жесть, спасибо
Денис Швейкин:
Так в итоге ту же самую ошибку на второй раз модель пропустила)
O1eD:
Эх, спасибо учительнице по математике! Решается такое уравнение в уме 2 секунды, используя мнемоническое правило: "проверь не является ли единица корнем сложив все коэффициенты". Спасибо Лидия Николаевна!
Stepan Bobrovnikov:
Красный хайлайт это ошибки? В 12 строке ошибку вижу, в строках ниже ошибка как следствие представлена? Новых ошибок не вижу
Сиолошная:
красный - где модель-оценщик стриггерилась и сказала "оцениваю это действие как неправильное". В 12й строчке действительно есть ошибка.
Dmitry Anikanov:
а есть сходство между PRM опенаи и Neurons антропиков ? silly question
Сиолошная:
ээээ Neurons это автоматическая интерпретация через автоэнкодер? нет
Stepan Bobrovnikov:
Модели постоянно допускают подобные ошибки, но часто указания на ошибку и короткого комментария, достаточно, чтобы модель исправила.
Проблема возникает тогда, когда на правильный ответ мы указываем как на ошибочный. Модель согласиться и примет ошибку.
Много работаю с кодом и моделированием сейчас. GPT4 - отличный помощник, но за результатом нужно следить и проверять
Michael Yudin:
Проблема формальной верификации программ так и не решена. Хотя попытки были и есть (например Воеводский со своим Coq)
hlomzik:
в 17 он вместо суммы использует произведение, сводя всё к нулю. правда, следующие строки уже должны быть либо все красными, либо все зелеными
Netizen:
Оценивается независимо каждое действие, на сколько я понимаю.
hlomzik:
это как-то противоречит моим словам?)
Некто:

Vasya the Cat:
Нам крышка.
Чуковский:
А раз может заменить ученого - значит, может заменить и разработчика
Сиолошная:
Про то, что якобы это работает на уровне школьных задач, я вообще не выкупил. Ещё в 21м году вон была статья про GPT-3, где она решала задач как 9-12 летние дети
https://openai.com/research/solving-math-word-problems
Sheridan:
Я как раз на пенсию пойду к этому времени, думаю :)
Мыcли очередного дата-сайентиста:
Но все ещё остается потребность в том, кто будет принимать решения, какие из гипотез проверять, а какие нет, после того как они проранжированы и очищены от мусора
Чуковский:
Особенно цинично было бы после этого поста увидеть рекламу какого-нибудь скиллбокс с курсами про войти в айти
Sheridan:
"Войти в АйИ" )))
Сиолошная:
от мусора очищаются решения.
То есть можно в теории сказать модели "Найди решение теоремы ферма" и просто посмотреть на выходное 250 страничное пособие
BOGDAN:
но ведь в единственном пока существующем доказательстве более 600 страниц математических выкладок
Мыcли очередного дата-сайентиста:
Это не отменяет того факта, что если нет того, кто может провалидировать решение, мы не можем гарантировать его правильность :)
Скорее это будет как дополнительный способ вдохновения или поиска иной точки зрения
Woland:
Луддиты
𝕆𝕃𝔼𝔾 𝕂𝕆𝕄𝔸ℝ𝕆𝕍:
Sam Altman was banned for supporting "unethical mathematical experiments"
Valeriy:
Есть другая конспирологическая связь Ильи с ФСБ и Яндексом... именно поэтому ЯндексГПТ называется... И ему хотели слить разработки, чтобы стали первыми.
Сиолошная:
ez compress
Alexander Dudin:
Надо первым делом направить такую прорывную модель исследовать и совершенствовать саму себя. После этого можно будет ее в борду OpenAI назначить, пусть вообще все исследования контролирует
Aleksandr:
Надо идти в фитнес-йога-инструкторы. Не получится там, так хотя бы в проституцию дорога открыта с six pack... Остальное все походу AGI за пару лет заменит.
Сиолошная:
ор
Чуковский:
Ещё в повара можно, роботы готовить точно не скоро научатся
Dinar:
Самая актуальная работа на первое время будет роботов собирать)
Sergey Samoylenko:
Nikita Sobur:
Вот это поворот будет когда AGI сам себя достроит. А потом будет зарабатывать на тренингах как создать себя с нуля без сторонней помощи)
Sheridan:
А мотом два раза моргнули а там уже ASI. Фьюить-ха!
Sergey Samoylenko:
Главное — верить в свои чипы и всё получится
Nikita:
Ну так-то и word2vec может делать открытия
https://www.nature.com/articles/s41586-019-1335-8
Чуковский:
Вы орете, а я знаю реальные случаи, когда обычные чуваки продажники на корпоративном обучении генерировали и зачитывали текст от чатжпт. Хотя целью обучения было научить ИХ продажам, чтобы они сами могли так говорить)
На вопрос «а клиенту ты тоже чатжпт дашь?», правда, ничего вменяемого не ответили, но процесс проверки знаний после экзамена был ооочень тяжёлым. Примерно как экзамен у студента по удаленке принимать
𝕆𝕃𝔼𝔾 𝕂𝕆𝕄𝔸ℝ𝕆𝕍:
После этого, зачем нам вообще нужны формулирования и доказательства теоремы Ферма, которые не сможет понять даже человек уровня Теренса Тао? Доказательства теоремы Ферма станут просто шагом в решении более глобального промпта.
Culture Иэна Бенкса наступает. Где мы просто чилим и просим.
А, ну еще строим сферы дайсона и ломаем всё до чего доберёмся, чтобы сделать больше "GPU".
What a Wonderful World
Andrey:

Сиолошная:
интересно, не подумал про это и то, что ОАИ играли с мелкими моделями
Алексей Абрамов:
Да нормально, айтишники будут в Северную Корею на заработки по специальности ездить))
Aleksandr:
Поехать в Сев Корею, что бы хакать Пентагон через чатгпт
Чуковский:
А то что эти graphs - просто эмпирически подобраны, ну типа как закон мура, мы конечно умолчим. Журналисты такие журналисты
Сиолошная:
не понял о чем ты
Petr Kungurtsev:
Jesus fucking Christ
glk2099:
Хуже, люди будут вместо производства гпу сдавать собственный мозг в аренду как гпу, чтоб заработать деньги.
glk2099:
Потом люди из-за этого в результате искусственного отбора будут иметь огромный мозг
BOGDAN:
черные лебеди нельзя предсказать
DixieF:
ну я и так сдаю свой мозг в аренду всю жизнь
Чуковский:
В твите написано «they have scaling graphs», в контексте, как будто OpenAI прям на 100% знает, что если вбухать тонну ресурсов в алгоритм, который решает математические задачки, то он гарантированно будет решать и более сложные задачи. Но на самом деле это ведь не так, все графики были построены для gpt-подобных сеток, никто не знает как это будет масштабироваться при других архитектурах
Nikita Sobur:
а так можно будет сдавать выгоднее))
glk2099:
Там будет полное подключение как в матрице))
Сиолошная:
1) про другие архитектуры речи не идет
2) всё, что говорит Scaling Laws — вот если есть столько компьюта, то будет вот так
3) пока нет ни одной причины полагать что Scaling Laws не работают
4) но я согласен, что мы эти выводы делаем эмпирически, по тем моделям, что у нас есть
5) но см. пункт 3
Борис опять:
Это нам должно очень повезти, чтобы сферы Дайсона строили мы
Сиолошная:
- а кто решил, что прекрасное будущее ждет ВАС?
Dmitry Anikanov:
Если сделать попытку спрогнозировать, то последующие года вычислительные мощности имеют темп роста, в виде обрастающих ЦОДов на точках энергогенерации. Верно же?
BOGDAN:
думойте…
Сиолошная:
ага
Dinar:
Да может найдут еще нормальные алгоритмы. Вон недавно же была новость что оптимизировали инференс для BERT в 70 раз.
Dmitry:
Это называется работа за зарплату
Dmitry:
Ох, боюсь не только решения будут очищаться
Dmitry Anikanov:
Всё стремится к fast-forward
Dmitry Anikanov:
Это суть чёрных лебедей?
Dinar:
Нужно просто пройтись по всем методам, где не O log n и попытаться сделать log n)
Некто:
интересно насколько такой оценщик может сложные мат доказательства анализировать - такой линтер реально бы помог ускорить валидацию результатов, даже если не получится сделать хороший генератор мат доказательств
Yr jn:
в начале было Промт Слово
Eduard:
Надо ещё сочинить квантовый алгоритм для моментального подбора весов вместо этих ваших бэкпропов и мизерных шагов
Здравствуй сингулярность
𝕆𝕃𝔼𝔾 𝕂𝕆𝕄𝔸ℝ𝕆𝕍:
"Мам я сегодня заработал свои первые 100$, но почему то после этого целый день думаю про фотки котиков, гачи хентай и как приготовить какое-нибудь блюдо из того, что лежит в холодильнике"
Вообще пока AGI не питается чисто на солнечных батареях, а мы не устроили блек-аут нам не грозит ни стать батарейками, ни GPUшками
Чуковский:
Хм, спасибо за прояснение) Почему-то решил, что Q* это абсолютно новая архитектура, которая сильно отличается от традиционных LLM, раз там так быстро прогресса достигли. Про остальные пункты по поводу скейлинга согласен)
Шубы:
Интересно какой станет аи после самосовершенствования через лет так тысячу?
Johnny:
Ну вот gpt по ощущениям задачи по математике, особенно нестандартные, пока очень плохо решает
Dmitry Anikanov:
Чёт про солнечные батареи не догоняю
LEAF:
Да, потому что не заточен на математику
𝕆𝕃𝔼𝔾 𝕂𝕆𝕄𝔸ℝ𝕆𝕍:
Распростарненый сюжетный троп про батарейки.
Сюжет фильма матрица (и отчасти Horison Zero Down): все люди использовались, как батарейки, потому что когда искины пошли против людей, правительства начали бомбардировки ядерными бомбами, чтобы смог закрыл небо и больше нельзя было питать солнечные батареи которые использовал ИИ.
Очередной говорящий Sapiens:
Что угодно говори, но он очень тупит в контексте, т.е он не выдает всегда нужный результат, что в программировании, что в статьях. Мне кажется, что ближайшее время симбиоз человек и машины будет лучше всего работать. Эффект привязки есть и у человека, но gpt все равно отвечает в контексте каких-то странных шаблонов и большие отчеты на 250 страниц будут связаны рамками которые были поставлены при обучении, а иногда нужно что-то другое
Dmitry Anikanov: А я наивно предположил, что типа АГИ машина останавливается при отсутствии человеческого любопытства
Yr jn:
но ведь Зион эт тоже часть матрицы....
D R:
Этот человек из твиттера стабильно всякие fake news постит
Сиолошная:
при этом я бы сказал что мысль здравая, безотносительно слухов. Что они на маленьком объеме что-то попробовали
Alex Ololo:
у меня такой вопрос. где прорыв раньше случится, в академических 78% решеных задач или на спекуляциих фьючами на фонд и валют рынках?
Сиолошная:
я не понел вопрос(
Neural Network World:
Как мне скормить гпт 4 гит хаб и получать потом фитбэк
BOGDAN:
скорми все файлы и структуру папок
Neural Network World:
я так и хочу
BOGDAN:
отлично, рад был помочь
Andrey:
На рынке вся потенциальная альфа после применения традиционных методов - инсайдерская, поэтому бейби аги у хфт с толстыми кабелями ничего не выиграет
Dmitry Anikanov:
правильно тебя понял, что вся магия уже спрятана за властным контролем вычисляющих чуваков ?
Yr jn:
а как получать фидбек?
Dmitry Anikanov:
фитбэк же
Yr jn:
сурен, фитбэк
BOGDAN:
попросить в конце?
Alex Ololo:
)) а если беби аги в т.ч. обучится у хвт выигрвывать? а что если у хвт у первых появится такой аги? я вот сулонен думать что бабки сильнее мотивирвуют чем создавать q star модель и решать математические задачки)
Alex Ololo:
сидит такой фонд с трлн денег и что он не думает как заюзать аги в своих целях?) ну рили? если мы помним, именно так эконометрика появилась) применение математики в экномике и тд и тп
Сиолошная:
какой фонд то? откуда у него AGI?
Dmitry Anikanov:
мне кажется кибернетика ближе по объясняющей способности
Александр Пятницын:
Вы подождите, пока эта тенденция до чувствительных областей дойдёт :) медицины, например. Вот тогда будет реальный треш. Вообще лично меня удивляет, что о прогрессе в ИИ говорят много и многие, а о социокультурных последствиях его массового внедрения - примерно никто.
Alex Ololo:
лишь предположение
Куликов Павел:
Все таки или выбран крайне неудачный пример, или.. Данная задача совершенно формальная, она дается на проверку понимания терминологии и базовых алгоритмов. На олимпиадном факультативе таких задач не встретить ни в каком классе. Mathematica такие задачи решает влет, единственно, они должны быть сформулированы на ее языке. Но вроде бы именно это к GPT4 давно прикрутили.
Этот пример годится для темы "мы научились решать еще пару типов задач нашим общим подходом", но этот вариант всегда будет уступать специализированному решению (а здесь оно есть, более того, есть связка универсальной оболочки и специализированного решателя).
Если все же говорить про ИИ, но начинать надо с чего то, что называют "сообразительностью". Уже почти год назад я давал ChatGPT (3.5) задачки для отбора на тот самый олимпиадный факультатив (примерно 4-5 класс), и он не справлялся совершенно, ни по английски, ни с подсказками (умеренными). Хотя намного более сложные темы вполне взрослой математики и физики излагал неплохо (не без отдельных глюков, конечно). Но применять не умел. Увы, я не вижу и не слышу о подобных работах в отношении GPT4, а сам пока тестировать коммерческую модель за свои деньги и за свое время не готов. Но именно эта задача из серии "вы ищите там, где не прятали", все это имхо, безусловно. Но если у них и остальные такие, то боюсь это от безысходности, потому что, кмк, это последнее, что придет в голову проверять. В общем, я скорее в недоумении (
Andrey:
Ну ёпт, а что если аги будет лазеры из глаз пулять, и заработает триллион на фондовом рынке предварительно убив всех человеков? У нас обоих глубоко спекулятивные тейки. Бабки мотивируют дофига, будь это ежегодный перформанс бонус или опционы на прайват сток. Я уверен, что финанс броз сжигают последний год очень много денег на ллмки, но мне не кажется, что у них это хорошо получается (из-за комбинации отсутствия экспертизы и того, что метод на задачу не оч хорошо ложится)
Dinar:
"Сообразительность" - это ведь не отдельное свойство интеллекта, а совокупность нескольких его свойств - насмотренность, внимательность, умение использовать накопленные знания и т.д. Я думаю даже GPT-3.5 по идее можно заставить находить решения, если увеличить контекст и научить следовать определенной логике прямо в контексте.
Dmitry Anikanov:
Всмысле!? Социокультурные последствия применения каждый день, в прямом эфире.
Кринж — стоять ещё, слушать о них)
Dmitry Anikanov:
В подобном контексте, нет уверености какое определение даётся словосчетанию "сжигают денег". Глобально же эти ярды выглядят просто двойной записью в бухгалтерии.
Александр Пятницын:
В прямом эфире они ретроспективно идут :) а хотелось бы проспективно. Ну вот из цитаты - начинающие продажники используют чатГПТ, чем это грозит для отрасли в целом на горизонте 3-5 лет? Как планировать жизнь конкретному продажнику?
DixieF:
фонтасты написали тыщи томов
Александр:
Так в йога инструкторы уже поздно
Александр:
Ну, за йога- и фитнес-инструкторов.
Доступ к API GPT-4Vision пошел в массы и самые невероятные примеры ждут нас в ближайшие недели.
А пока полюбуйтесь, что вытворяет в одно лицо за несколько часов смышлёный малый.
Ну то есть за день теперь можно изваять MVP, на которые фитнес-стартапы тратили месяцы и мильоны. На этой неделе они заплакали и пошли спрашивать chatGPT как лучше пивотнуться подальше от компьютерного зрения, на территории которого обугленные останки ресерчеров, PhD, стартапов, грантов и других постраданцев от чорного ИИ-понедельника 6 ноября.
P.S. Берём старика Айенгара (благо материалов есть) и делаем строгий yogaGPT, который следит, чтобы локти не разводились и шея не заламывалась.
И чтобы кожаные инструкторы ничего от себя не добавляли - а то потом появляются всякие аштанги или 23, от которых в момент вылетают плечи и прочее.
Только ИИ-айенгар, только канон!
Ну или ВСБ для скрепных территорий.
Dmitry Anikanov:
Согласен. Но и наше сознание, которое выражаем языком, "объяснтор" перцепции мира.
В той цитате, продажники успешно проходят практику) думаю это сакцесс стори (успешного успеха) общаться, предлагать, практиковать элаймент...
Моё возражение лишь на то, что социокультурные последствия слишком естественный процесс природы.
Txomas:
Было бы здорово если бы так, но чё то не верится. Обычно чат гпт не так быстро отвечает, а тут ещё анализ картинки + даже на видео видно что человек херово влазит в камеру, нужно будет вечно попровляться. Да и ответам не то чтобы можно верить
Александр:
Да, это пока хайп и преувеличение. И в чатике метаверсошной, откуда этот пост, все те же недостатки накидали.
Но на мой взгляд главное не это, а мысль что учится чему то связанному с умственными задачами уже поздно. При обучении 5+ лет. Хотя посмотрим как дальше дело пойдет.
Но на фитнес инструктора побыстрее можно выучиться.
Txomas:
Не понял откуда эта мысль исходит. А чему ещё учиться тогда?
artur:
Ну если бы "ОН ЧТОТО ТАМ УВИДЕЛ" то никто его точно бы не уволил. Иначе инфа точно выплыла бы наружу поэтому аерсия с чтото увидел и чтобы это скрыть его уволили выглядит не логичной.
Наверно научили ии исследования проводить простейшие самостоятельно мне кажется самоай пробдоподрбная версия
Moon-Watcher:
Очень много об этом говорят и пишут.
Artem L.:
Если не фитнес-инструктором, то кем быть после ИИ революции? Фермер, электрик?
Александр Пятницын:
Я буду благодарен, если вы поделитесь ссылками )
BOGDAN:
Повар?
DixieF:
все будем в поле трудится, загорелые, довольные
Dmitry:
У вас не будет ИИ-революции, если труд человека у вас в стране в принципе стоит настолько мало, что его невыгодно заменять :)
Moon-Watcher:
Ну хотя бы вот: https://gadgets-news.ru/stanet-li-ii-bb/ О будущих социальных последствиях от ИИ не говорит сейчас только ленивый.
Dmitry Anikanov:
Фильм завершается закадровым монологом (вновь цитатой из Уэллса), где рассказывается, что инопланетяне умерли, заражённые микроорганизмами, населяющими Землю, с которыми человек сосуществует уже долгие тысячелетия и, в отличие от пришельцев, обладает иммунитетом к их воздействию.
Txomas:
Если это не шутка, то искренне не понимаю этих вопросов. Вся суть подобного развития технологий разве в том, чем уже многие люди занимаются сейчас: постоянное обучение и смена деятельности. Просто все больше людей будут менее привязаны к своему текущему стеку и месту работы, все больше людей будут изучать новое и менять вид деятельности все чаще да и все
Dmitry:
Это вообще грустно довольно, потому что пластичность и адаптивность у людей просто от природы сильно варьируется, а ещё с возрастом снижается, а от растущей прекарности занятости все и так уже охреневают.
Txomas:
Так вроде с возрастом снижается как раз у тех кто в течении жизни не пластичен был
Artem L.:
Кто-то поменяют сферу работы, но много людей окажется на обочине жизни, даже базовый доход не сильно исправит ситуацию. Миллиард людей без цели и перспектив все сметут
Dmitry:
И та же современная западная молодëжь в большинстве своём завидует стабильной и высокодоходной жизни поколений своих родителей и очень грустно воспринимает своë текущее всë менее стабильное положение в жизни на фоне лёгкости жизни их родителей десятилетия в прошлом.
Dmitry:
Навскидку не найду, но кажется, попадались исследования, что это не только поколенческие, но и возрастные эффекты.
Dmitry Anikanov:
сметут с полок, или с лица земли?)
Txomas:
Да ладно, такие пугалки вечно про все технологии, не первый же скачок будет, уже в курсе что это и как с этим работать, и даже в предыдущие разы ничем прям катострофическим не оборачивалось. Тут я не спец в любом случае, могу разве что сказать что это явно не выглядит ужасной проблемой
Dmitry Anikanov:
Я топлю за то, что уже всё случилось! Ретроспективно об этом узнаем из исследований исскуственных учёных
Txomas:
Ну это совсем уже звучит как субъективщига и что-то сложно измеримое и сравнимое. Как-то опираться на чувство зависти совсем не рабочий вариант
Andrey:
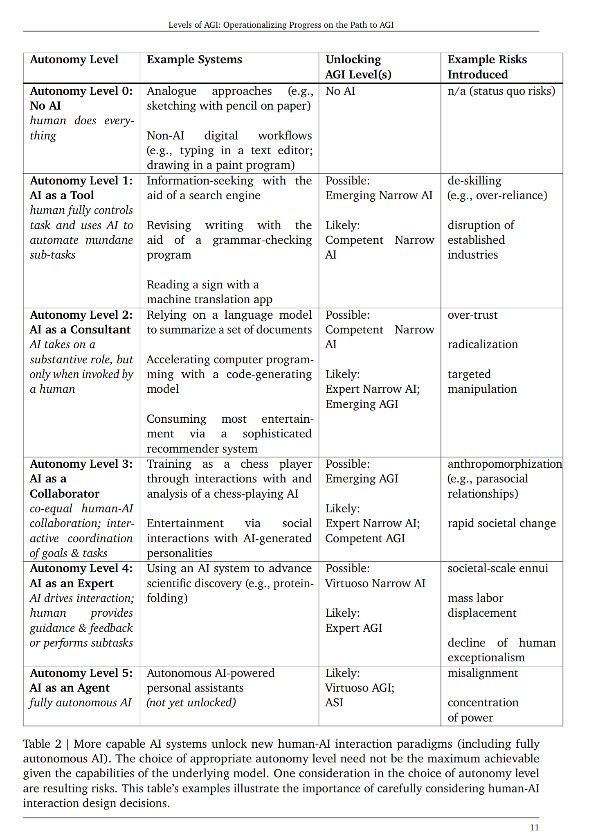
Мне понравилась формулировка из недавнего пейпера: societal-scale ennui
Dmitry Anikanov:
Dmitry:
Ну как сказать. На рубеже 2000 года 70% в США считали, что они проживут жизнь лучше, чем свои родители. Теперь только 40%. Похожая динамика по другим странам.
https://thehill.com/changing-america/well-being/longevity/3702950-optimism-about-next-generations-ability-to-have-a-better-life-than-parents-drops-gallup/
Txomas:
ну вот это уже более разумно звучит и как что-то на что можно опираться) а не завидуют/грустят
Кука Тверской:
https://www.youtube.com/watch?v=SXiJLqcfe68
Michael Yudin:
До самостоятельного доказательства теорем еще ого-го как далеко. Пока хотя бы научить модель проверять чужие доказательства . Для того, чтобы модель могла что-то доказать или проверить чье-то доказательство - сперва необходимо формализовать систему, в которой теорема и доказательство записаны.
Желающим углубиться в эту тему могу посоветовать почитать о Гротендике, или о Воеводском и его "унивалентных основаниях математики". А так же попробовать описать какую-то простейшую теорему и ее доказательство в Coq, например.
Если бы нейронки могли доказывать или хотя бы проверять доказательства - это был бы огромный прорыв. Сомневаюсь, что OpenAI близок к этому (((
Игорь:
Спасибо за лекцию, интересно!
Кстати, вы в ней предсказали сегодняшнюю новость о способности google bard пересказывать видео с ютюба.
OA:
Коля Давыдов и Либерманы
https://www.youtube.com/watch?v=boF1n3EBGtc
Сиолошная:
https://t.me/c/1778093200/50525
OA:
Не кликается линк. Было уже?
Txomas:
Кто это
Сиолошная:
должен кликаться
OA:
согласен
Roman Gailit:
Пугает что борд, который якобы представляет сторону "AI safety and slow down" (что в вакууме звучит логично) -- обосрался по всем фронтам и теперь сам нарратив может быть похоронен. Вперёд к рискам и профитам на полной скорости с СЕО который доказал что он неубиваем
Сиолошная:
вообще не пугает
Roman Gailit:
AI safety не нужон?
Сиолошная:
я говорю, что эта повестка не изменится и не будет похоронена
Roman Gailit:
надеюсь, но баланс сил явно качнулся не в сторону повестки
Сиолошная:
вообще не факт
OA:
this
Roman Gailit:
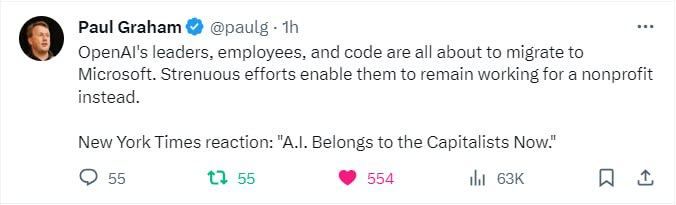
Как воспринимать тот факт, что 95% компании готовы были публично уйти в for-profit Microsoft? Там тоже AI safety на первом месте бы была?
BOGDAN:
кажется руководство, миссия + культура перешли бы вместе с людьми
Сиолошная:
воспринимать так:
— они не перешли
— ни ты ни я не знаем уровня автономности, который предложили бы этой подкомпании. Про гитхаб и линкедин люди говорят, что они сохранили всю свою культуру, и мсфт на них не давит, не считает, что это внутренний отдел.
— они подписали письмо в котором говорилось "суки отдайте нам наш нонпрофит, или мы уйдем".
- в борде сейчас ни одного кофаундера компании
- задача борда набрать нвоый борд, сохраняющий ценности компании
- картинка
Dmitry:
Да вообще штат компании разочаровал. У них чётко миссия задана, они почти все готовы были на неё жирно болт положить ради своего дуче.
Andrey:
был эвиденс, что эти 700 человек не просто в выходной скроллили твиттер и решили подписать, а что их прессинговали. Был удаленный твит о том, как человек гордился тем, что обзванивал коллег ночью
OA:
Ну, понеслась
OA:
Я нет, мне можно сказать
James 😎 Dean:
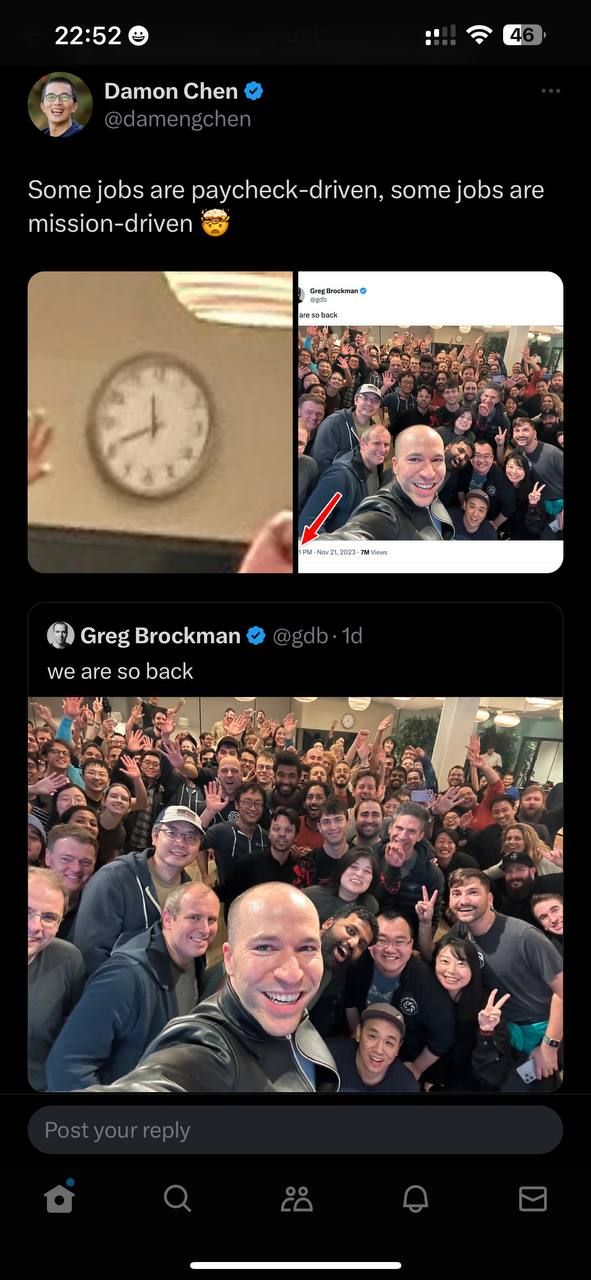
Так у нас новая conspiracy theory
Sheridan:
Позовите разъяснительную команду, пожалуйста...
James 😎 Dean:
Link
В Кратце время разное на часах и время поста
James 😎 Dean:
Ну это уже дурка
Adv0cat:
бан
James 😎 Dean:
Я уж думал мне
Adv0cat:
теперь выглядит, как вроде бы я ебанутый
Andrey:
а кто будет следовать миссии, если сейчас борду дефангнут, а СЕО получит полноту власти? как будто шо так, шо эдак, миссии кирдык
Txomas:
не может получить полноту власти, борда энивей будет, чтоб ее прям убрать нужна реструктуризация компании которую так просто не сделать
Txomas:
да и вообще, так написано как будто только борда миссии и следуют а остальные просто ей подчиняются и такие эх ну так и быть
Алексей Земсков:
На самом деле, я всё ещё думаю, что люди сильно недооценивают сам факт возвращения Сэма Альтмана в OpenAI, при рассуждениях насчёт прорывных технологиях, которые есть у OpenAI.
Вопрос ЗАЧЕМ Альтману возращаться в non-profit компанию, где у него 0 денежного интересна и он наемный сотрудник, если последние дни ну супер явно показали, что он мог бы собрать легко миллиарды долларов и ещё и захантить 90% OpenAI сотрудников под СВОЮ компанию. Либо получить должность главы исследовательского направления Майкрософт со всеми их огромными ресурсами?( они на 50 миллиардов инфраструктуру строят к той что уже есть)
Мне кажется, что это вообще нетривиальный вопрос. Альтман не дурачок какой то. И размышляя об этом, я нахожу рациональным такой поступок, только если он сам видит достаточно короткие сроки появления AGI, и считает, что откат даже на пол года уже может быть критичным
Andrey:
для алтмана создание собственной компании было бы контрпродуктивно -- зачем терять людей, прогресс, ресурсы, уже установленные сделки ради чего-то, что очень похоже на то, что у него уже есть. В чартере прописано, что у борды не должно быть акций, а теперь алтман не на борде. Я думаю, даже если бы он оставался, и не держал бы прайват стока сам, невозможен сценарий, в котором ему ничего бы не перепадало от валюации в 80б
уход в МС тоже был бы контрпродуктивен -- если ты тут бога рожаешь будучи сио лидирующей компании, випи в обычном фаанге (у которого ооооооч ограниченный потенциальный апсайд стока) это большой даунгрейд
OA:
У Альтмана может быть несколько рациональных резонов (об остальных что говорить, мы его лично не знаем)
1 Есть сильнейший бренд в домене. Таким не разбрасываются
2 Есть фантастически работающая модель взаимодействия лучших умов, и хз получится ли ее так вот легко воссоздать, потому что создание новой компании со всеми пирогами - это шок. Часть людей может отвалиться, другая часть снизить эффективность
3 Уникальное положение (доказано) - их хотят буквально все. Зачем такое положение подвергать хаосу неизвестности? Может, стоит потратить усилия на прогресс и использование возможностей?
4 Чувак буквально участвует в создании будущего. Блин, тут какие еще аргументы нужны
5 Он и так ебанистически богат, и в этом контексте давно находится за горизонтом событий для наблюдателей с этой стороны
1:
А возможно ли такое, что среди прочего также имеет место быть в том числе и некое политическое давление/манипуляции? Сэм ведь значительное время потратил на взаимодействия с верховной властью в стране. Моги ли там помимо анонсированных встреч/слушаний также быть контакты и со спецслужбами, военными, какими-то комитетами безопасности? США хоть и очень демократична в плане соблюдения личных и гражданских свобод, но тем не менее умеет во всякие манипуляционные игры, особенно если от этого зависит положение всей страны (как минимум) на международной арене влияния. И если для достижения такой цели потребуется "завербовать" одного-нескольких влиятельных в сфере ИИ фигур, то почему бы и не рассмотреть этот вариант?
Или может я просто "Карточный домик" пересмотрел.
John Toshin:
Имхо, вербовка отнюдь не повышает креативность и эффективность основной деятельности вербуемого (ибо как минимум отвлекает внимание). Для укрепления положения страны на мировой арене значительно выгоднее быстрое развитие своего лидера, чем его контроль. Вербовка имела бы смысл в случае сомнений в лояльности, но отрицательные последствия этой вербовки были бы очевидны сторонним наблюдателям. А риск утерять первенство вполне себе существует.
Oleg Baranov:
Я вижу ситуацию, как в революционной песне: "Если сингулярности, то мгновенной. Если AI Winter - небольшой".
James 😎 Dean:
У меня весь ютуб забит Q* is the BIGGEST
Ivan Podpruzhnikov:
Так учёные (не дата саентисты) сильно дешевле, чем апи
А ещё молодые учёные могут тяжёлые компьютеры на горбу таскать
Так что наука не потеряет специалистов)
Adv0cat:
2 years later...
Anton:
ты считаешь всю стоимость производства 1 ученого, с рождения?
Oxana Steba:
Если не сложно, ссылку можно на эту новость?
Dinar:
https://t.me/c/1778093200/49389
Oxana Steba:
Спасибо!
Дияна:
Не хочу читать 200 сообщений; какой профессии начинать учиться, чтоб работа была через 30 лет тоже?))
DixieF:
через 30 лет все будут делать роботы, они будут платить налоги, а вы будете жить на безусловный базовый доход
Txomas:
Так суть как раз в том, что скорее всего не будет такой вот вечной работы. Учиться стоит работе которую потом можно будет сменить на другую)
Борис опять:
плотник, сантехник, фермер
Ara Israelyan:
Про плотника - глубоко...
1:
Тоже часто размышляю о таком. Есть некоторые предположения. Например, считаю, что вполне вероятным останется интерес кожаных к спортивным соревнованиям, как к состязательным, так и к игровым тоже (и личным и командным). Ну, например, возьмём футбол: какие бы совершенные роботы-футболисты не будут созданы, всё равно есть вероятность, что у кожаных так и останется интерес смотреть на СВОИХ, и болеть именно за них, со всеми их несовершенствами и путями спортивного развития. Или же например состязания по скорости бега, плавания, точности стрельбы - во всех этих дисциплинах уже давно прогресс придумал то, что многократно превосходит человеческие возможности, но всё равно землянам интересно наблюдать как всё таки далеко могут зайти именно ЧЕЛОВЕЧЕСКИЕ возможности. Да или даже например автогонки. Уже сейчас их автоматизированная версия с ИИ уже лучше человеческой (и быстрее, и точнее и красивее), но земляне почему-то продолжают смотреть на формулу-1 с кожаными мешками за рулём. Азарт, болельщики, фан-клубы - всё это склонно будет образовываться всегда вокруг своих же живых землян, а не искуственных суррогатов. Так что карьера профессионального спортсмена это одна из нескольких, кто вполне может иметь шансы в 1-2% остаться после наступления технологической сингулярности.
1:
Следующие из моих вариантов - это что-то сугубо очень ремесленное.
Но эти варианты - они для того случая, если будет экономический достаток у людей в обществах будущего.
Выше уже предложили сантехника и фермера, но эти двое очень спорно, так как эти должности слишком утилитарны, и идеальная обученная автоматизация однозначно их вытеснит из экономической модели.
А вот предложенный рядом плотник - уже ближе. Но это не тот плотник, который ходит по квартирам из жэка и чинит окна, а тот, который "творит". Сюда же, кстати, и все остальные более артистические "творцы" (художники, музыканты).
И тут дело не в том, что ИИ (или роботы) не смогут делать лучше. Они как раз таки и смогут делать и красивее и креативнее, а дело в том, что среди землян, вероятно (!), останется интерес к тому, что "сделано настоящими живыми человеческими РУКАМИ".
Уже сейчас ИИ создаёт картины-шедевры высочайшего качества за 1 секунду, но когда они настолько стали доступны, что их стоимость равняется ничему, то, наверно, имеющий деньги человек не станет их распечатывать на принтере и вешать на стену, а купит для украшения своей спальни то, что было СОЗДАНО творческим длительным процессом, что имеет хоть какую-то авторскую историю, "имеет душу".
Тот же плотник из начала сделает журнальный столик или резной платяный шкаф за время в 5000 раз дольшее, чем робот с ИИ, но зато это будет изделие именно от "мастера", от "творца", и для землян с деньгами, вероятно (!), это будет важно, и они будут готовы за это заплатить.
Уже сейчас на заводах выпускается идеальная керамическая посуда, но почему-то есть небольшой спрос и на вручную изготовленную гончарную глиняную посуду (кривую и блеклую при пристальном изучении), хотя она и стоит дороже (как раз из-за того, что она сделана РУКАМИ ЧЕЛОВЕКА).
Dinar:
Столяр называется)
Maks:
Любой онлайн бизнес, работу в котором можно будет полностью заменить AGI/LLM обречён на банкротство, потому что если упростить бизнес до такой степени, что его можно полностью делать LLM, то его смогут скопировать все
Ilya:

Исправляют ошибки
DGN:
Техник-наладчик машин времени. Работа и через 30 и через 300 лет.
DGN:
Но это не точно...
BOGDAN:
бан
1:
А есть где-то список правил/критериев, по которым выдаются баны? А то меня за что-то забанили здесь на основном акке, и теперь приходится с фейка читать обсуждения.
Adv0cat:
Баан
Be:
У всех веб-версия умерла?
James 😎 Dean:
у меня работает
Bari:
Всюду сплошные угрозы человечеству,как же достали
Michael K.:
А потом модель сожжет стопицот мильенов денег и выдаст 42 :)))
VitaNostra:
А Игорь куда пропал так резко? То прям чуть ли не часовые сводки с фронтов OpenAI, а сейчас - ни одного обновления с четверга...
BOGDAN:
Игорь играет в Квест3, не отвлекайте
Mike:
мы требуем новых сиолошных постов
Сиолошная:
мы к ночи готовимся
BOGDAN:
подрядчик инфоповодов (OpenAI) проебался по срокам, обещают только завтра
Сиолошная:
мне прсото платежка не пришла за проплаченные посты от опенаи, теперь бойкот
видимо попутали что-то в суматохе с бордой
BOGDAN:
сколько битков?
Сиолошная:
6
Adv0cat:
А ноликов?)
BOGDAN:

Архив блога:
О сайте:
Мои соцсети: